Optimizing generic algorithms
Denis Yaroshevskiy
Disclaimers
- No affiliation with the mentioned projects
- What I know is pieced together from my experiments and the Internet
- One compiler, one machine
- Beware of bugs and issues
- Some of my statements are opinions
Goal
What can you do if your performance bottleneck is a general purpose utilitly
Why listen to me about this?
-
Have a couple of accepted patches to libc++
(and more not accepted) -
A few interesting contributions to
Chromium's base library - Microbenchmark algorithms (quite a lot)
Overview
- microbenchmarking
- partition_point(lower_bound)
- merge
- stable_sort
Microbenchmarking
- Watch Chandler's talk: Tuning C++: Benchmarks, and CPUs, and Compilers! Oh My!
- Google Benchmark works for me
Biggest problem of microbenchmarking
live_demo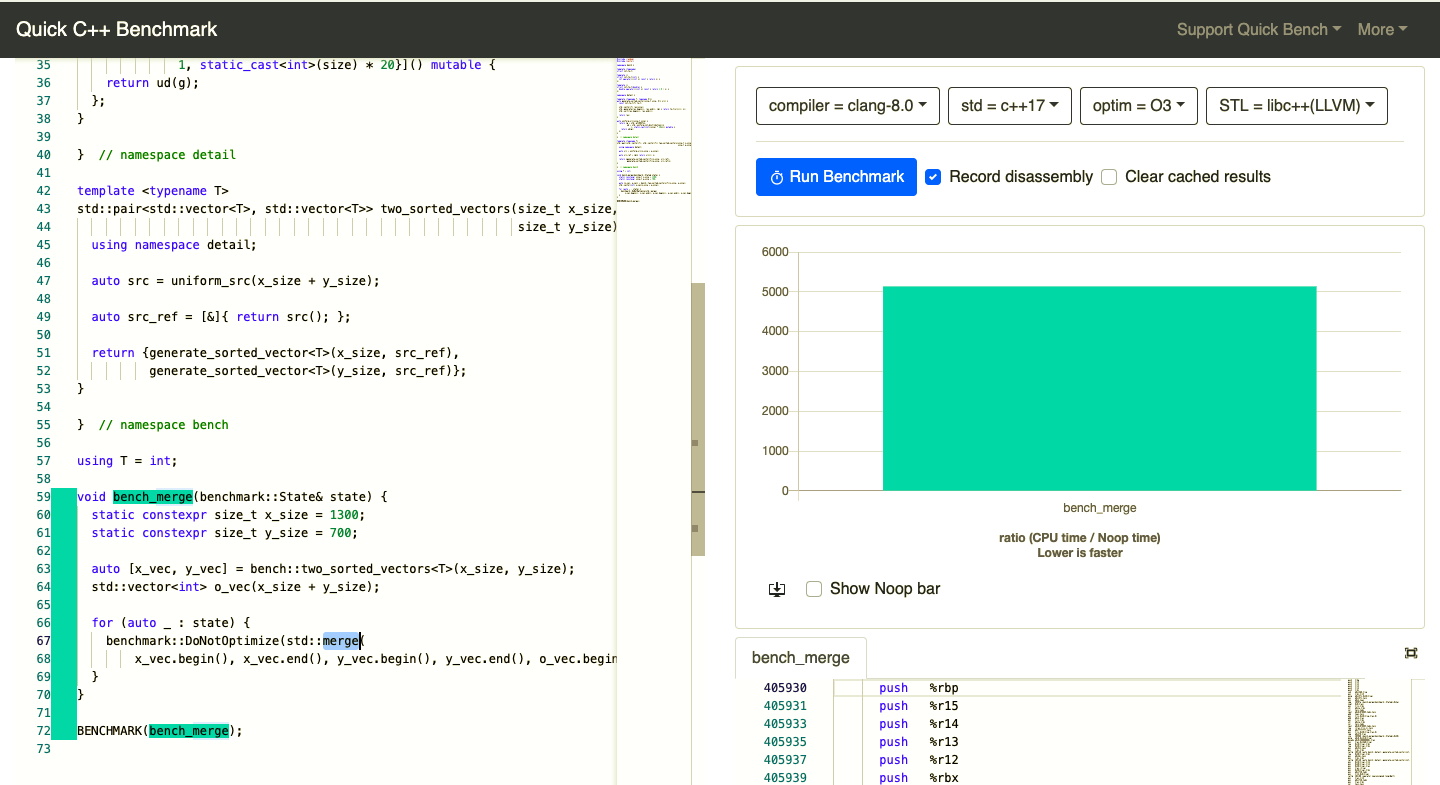
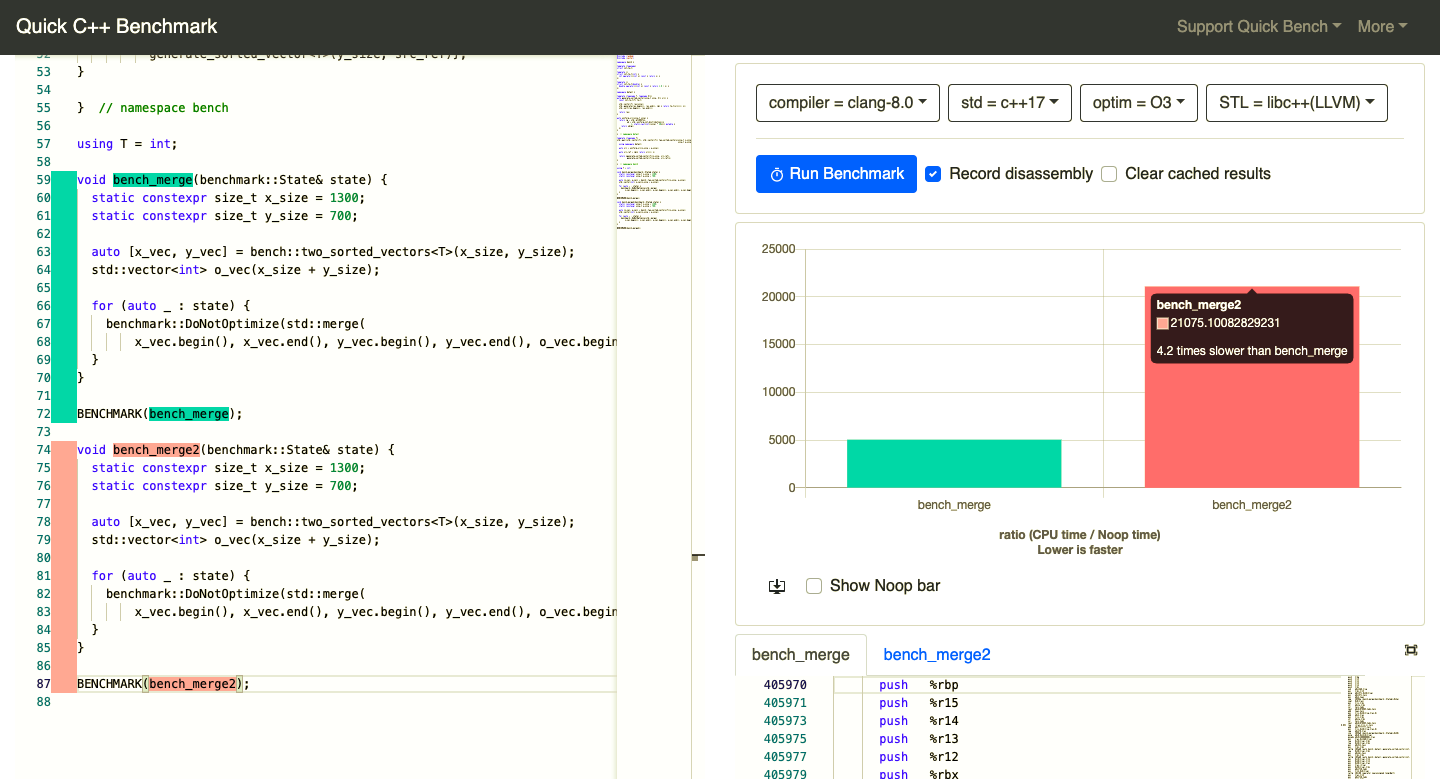
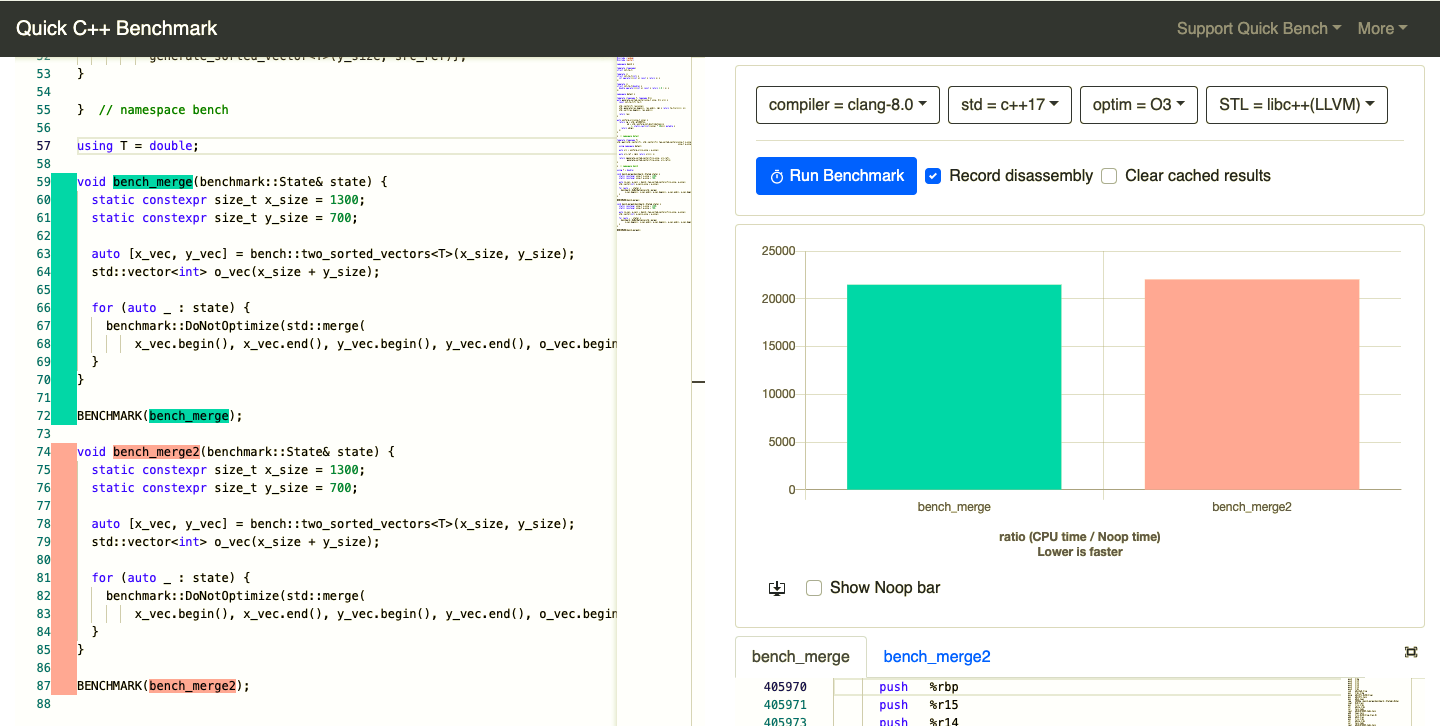
Bad news
- Can be 4 times slower
- No known solution Google Benchmark issue #461
- Happens in production code
Good news
- Difference is huge
- Very unstable
What to do about it
- One benchmark per binary
- Tweak your code (run for similar types)
- On Linux, there are tools
- Denis Bakhvalov:Code alignment issues
partition_point
(lower_bound)
What affects performance of a binary search?
- Range size
- Which element are we looking for?
- Predicate
- Distribution of data
- Non-templated operations
- Cache locality of data
- Binary size
Start with an optimization
- Pick 1 or 2 "fundamental" benchmarks
- Add a benchmark for your optimization
- Add benchmarks that could have been negatively affected
Suggested optimization
Suggested optimization (no CE)
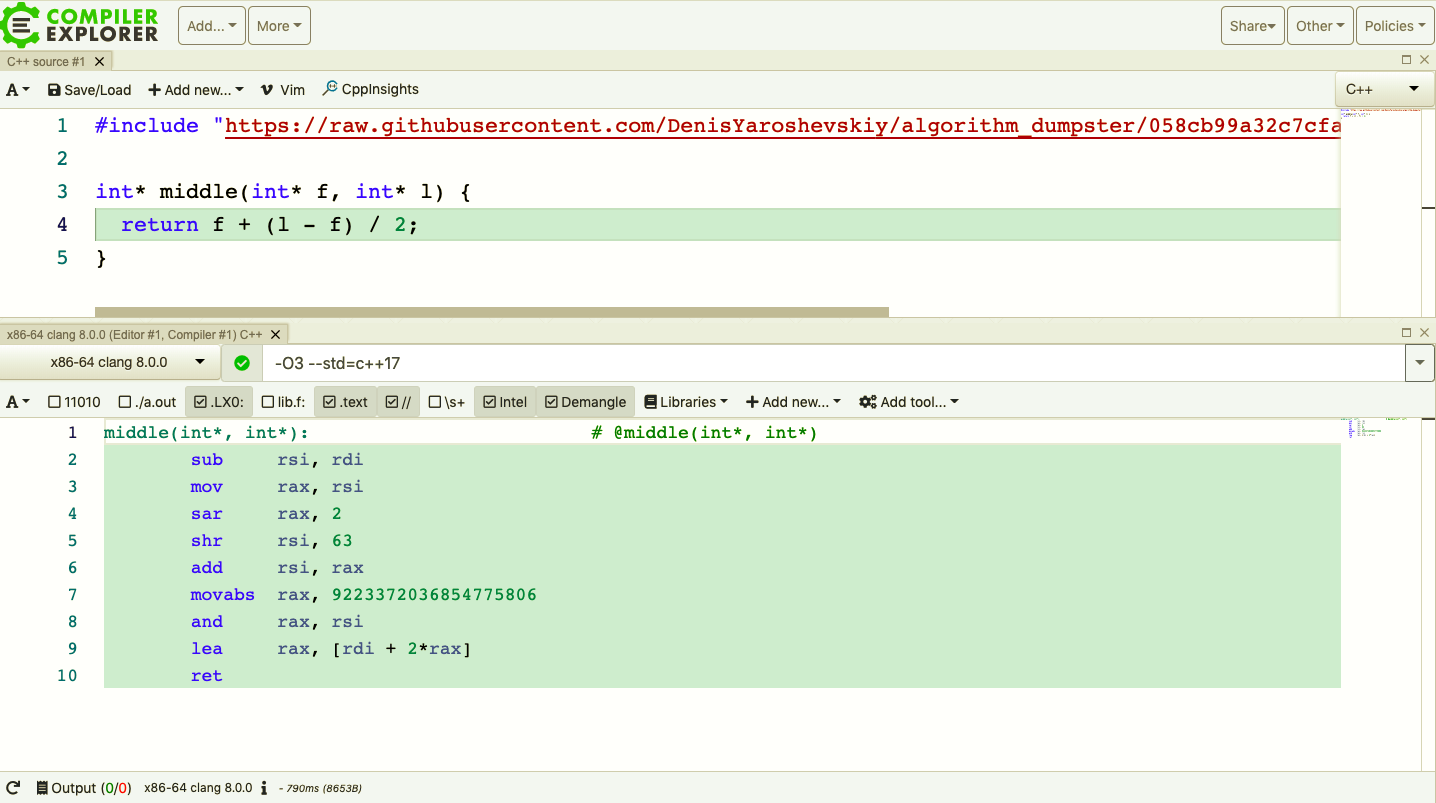
Suggested optimization (no CE)
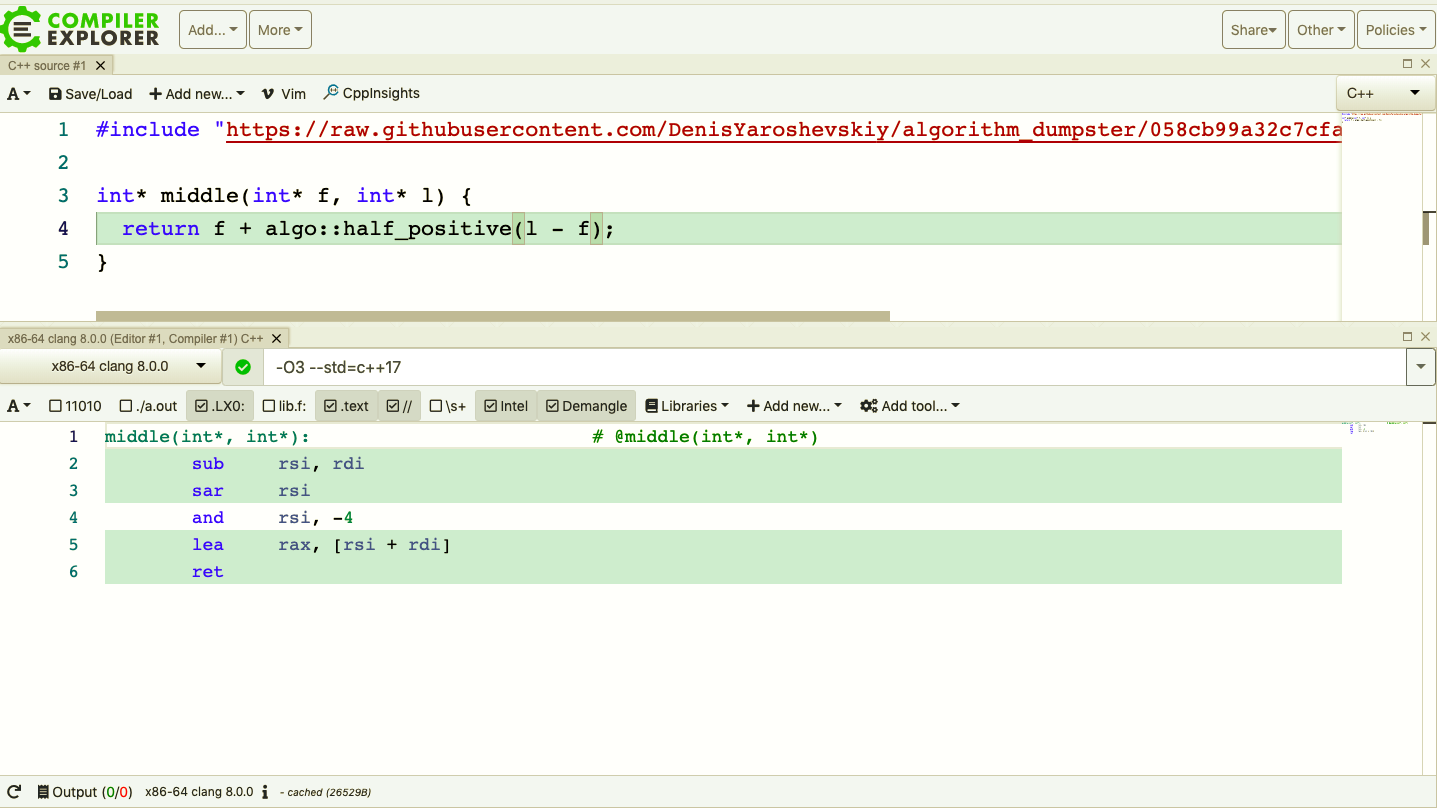
What did we affect?
- Non templated operations
- Binary size (-2 instructions)
Basic binary search benchmark
- Binary search a 1,000 integers
- Parameterized on element to look up
- Double-check on int64 and doubles
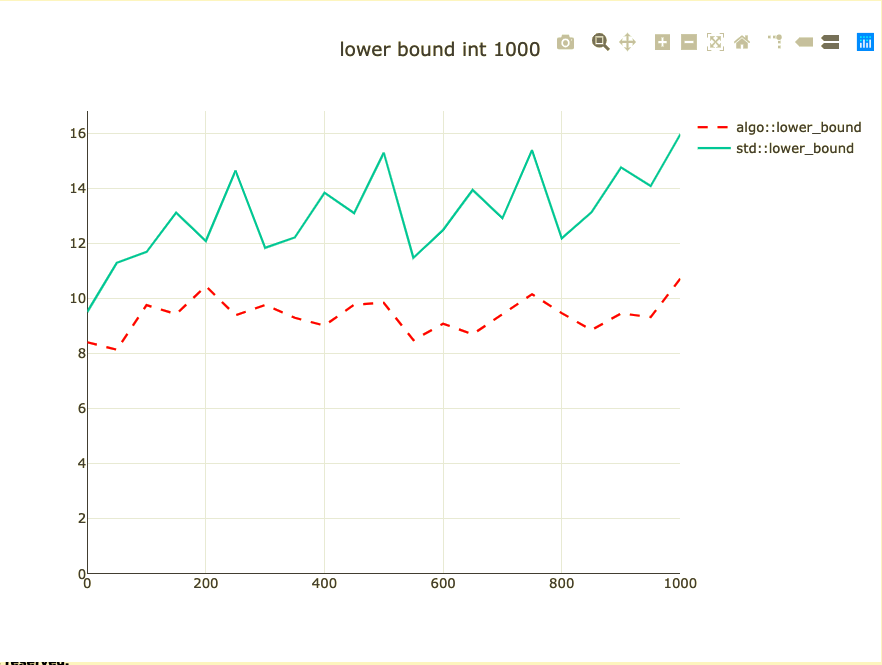
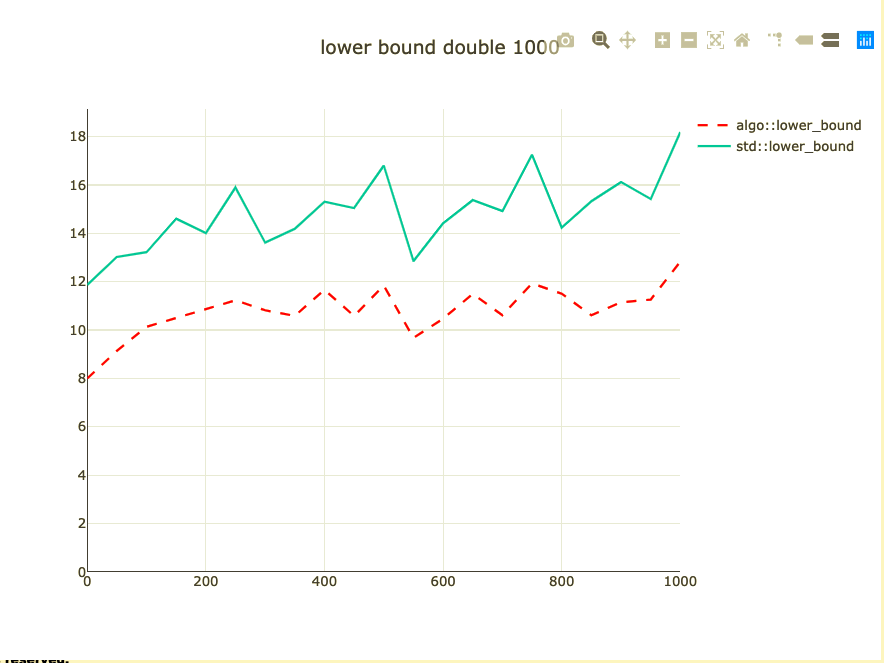
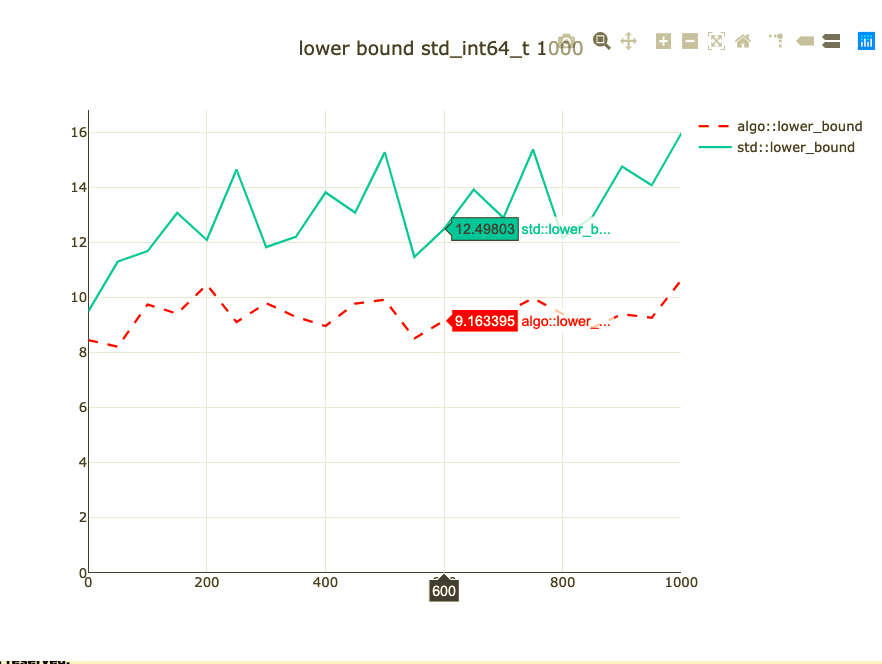
- half_nonnegative has landed in libc++
- Between linear and binary search
- flat set vs. flat_hash_set
merge
What affects performance of merge?
- Total size
- How elements are mixed
- Comparison
- Move
- Non-templated operations
- Cache locality of data
- Binary size


What did we affect?
- Non-templated operations
- Binary size (+ 11 instructions ~20%)
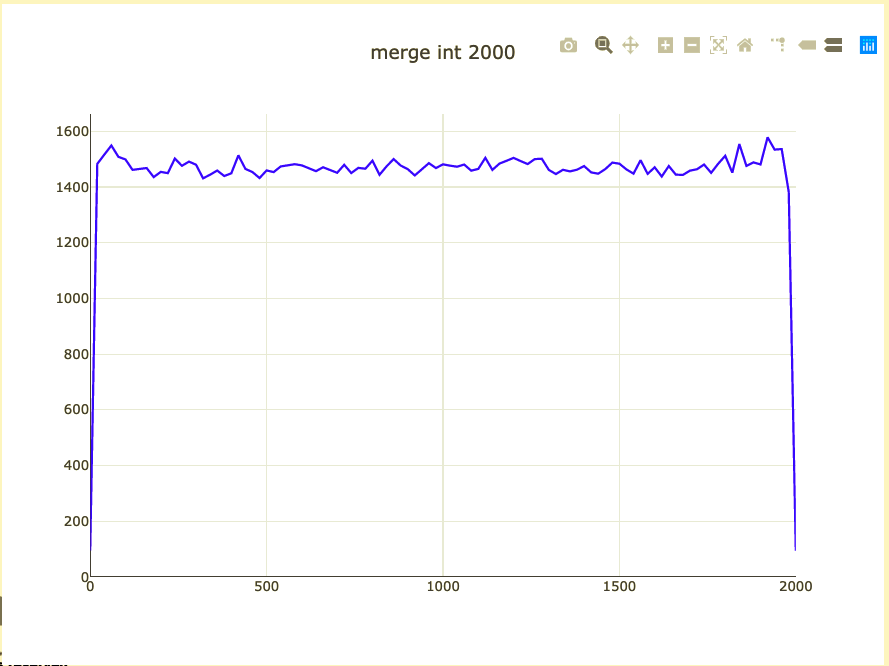
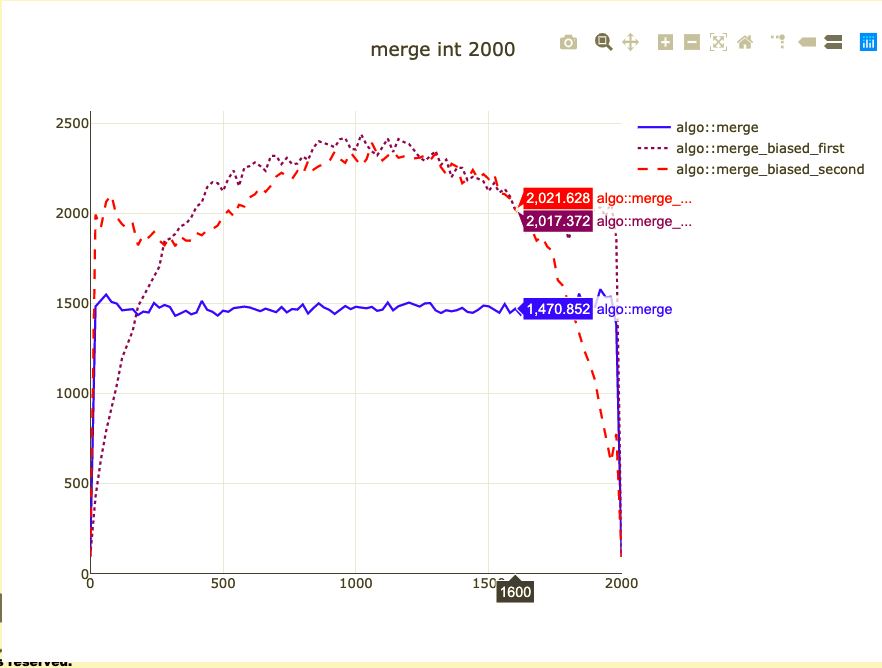
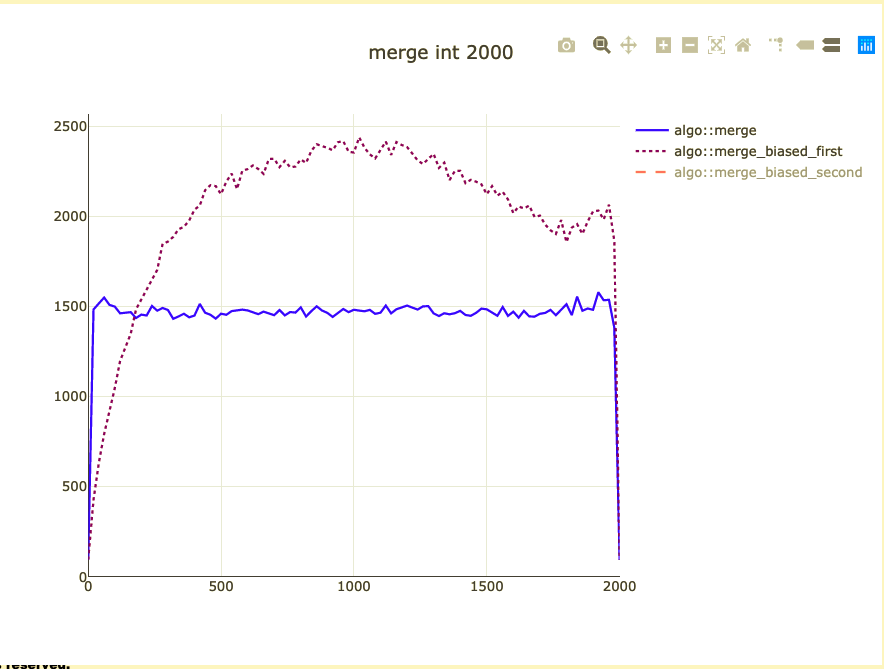
Basic merge benchmark
- Merge 2,000 integers
- Parameterized on 2 sizes (represent distribution)
- Double-check on int64 and doubles
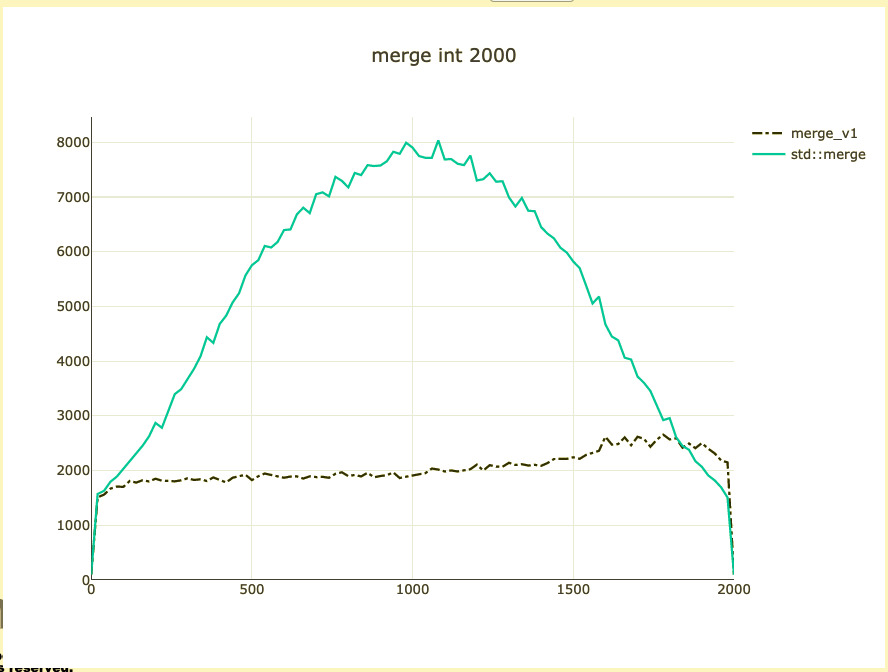
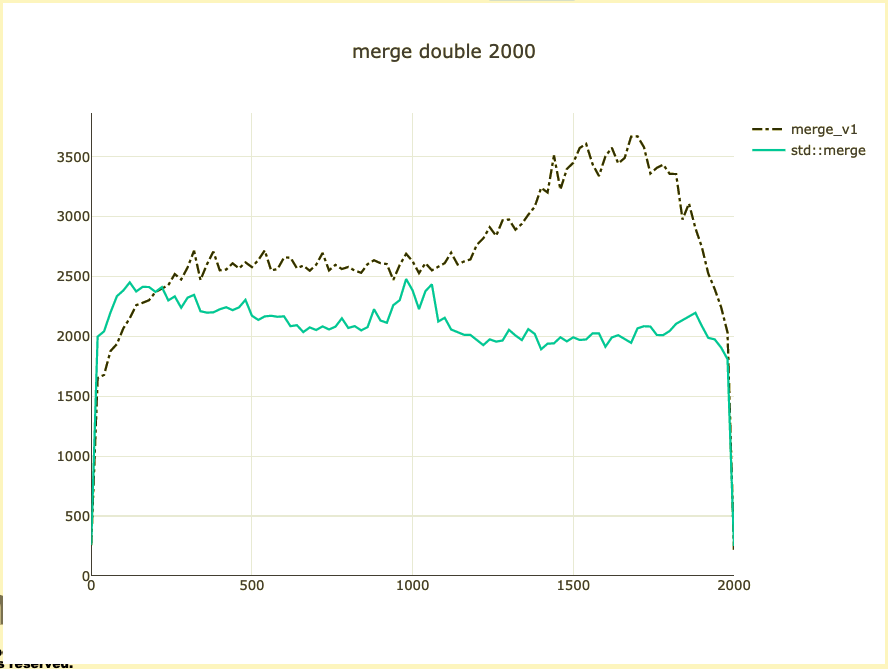
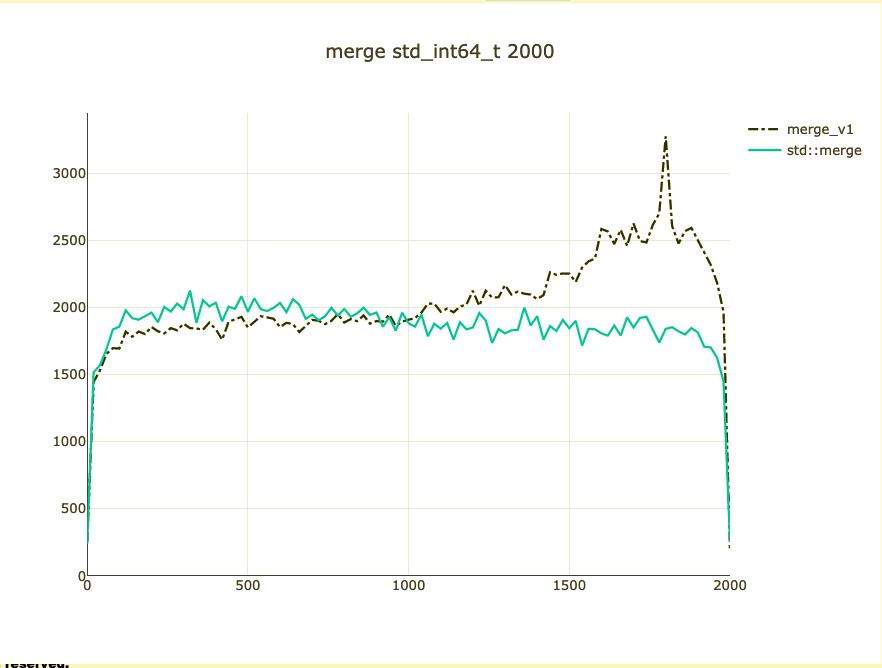

What did we affect?
- Extra comparison/assignment
- Non-templated operations
- Binary size for ints (+ 10 instructions ~20%)
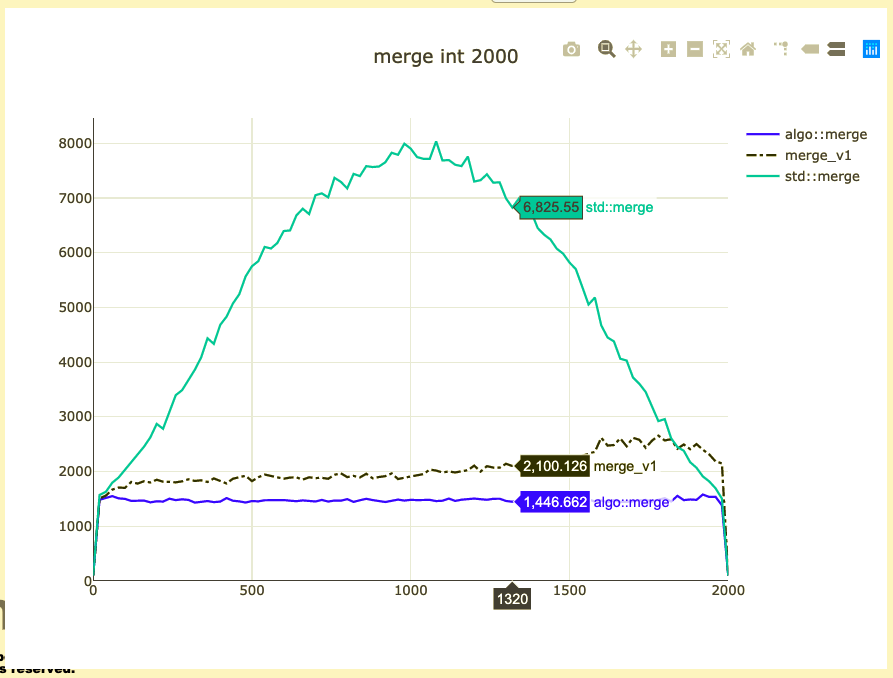
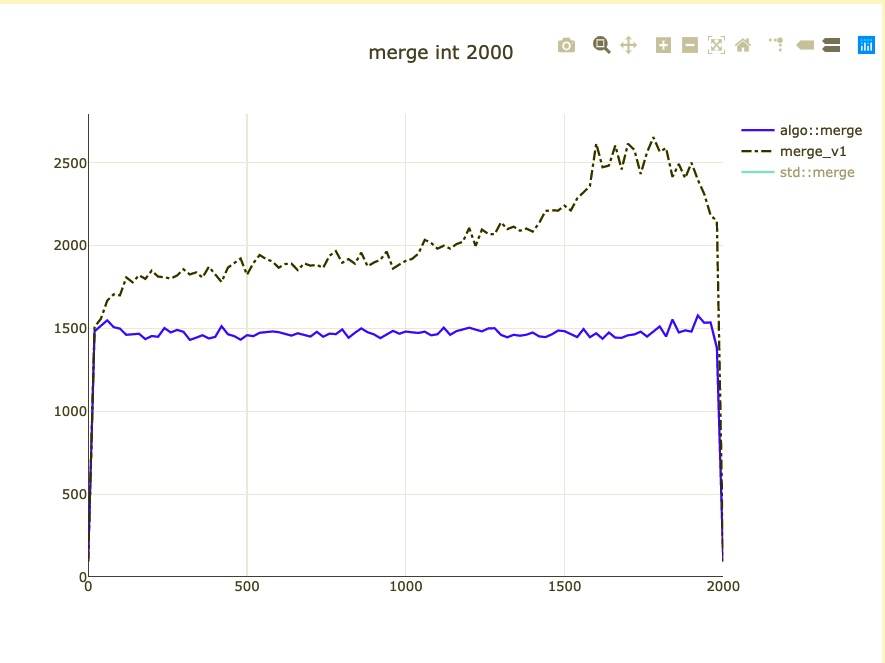
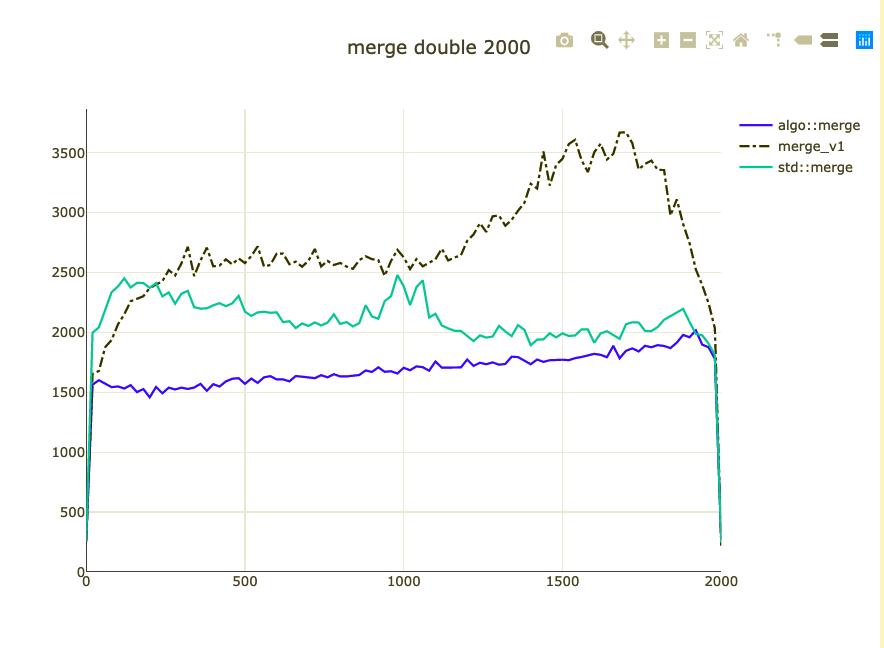
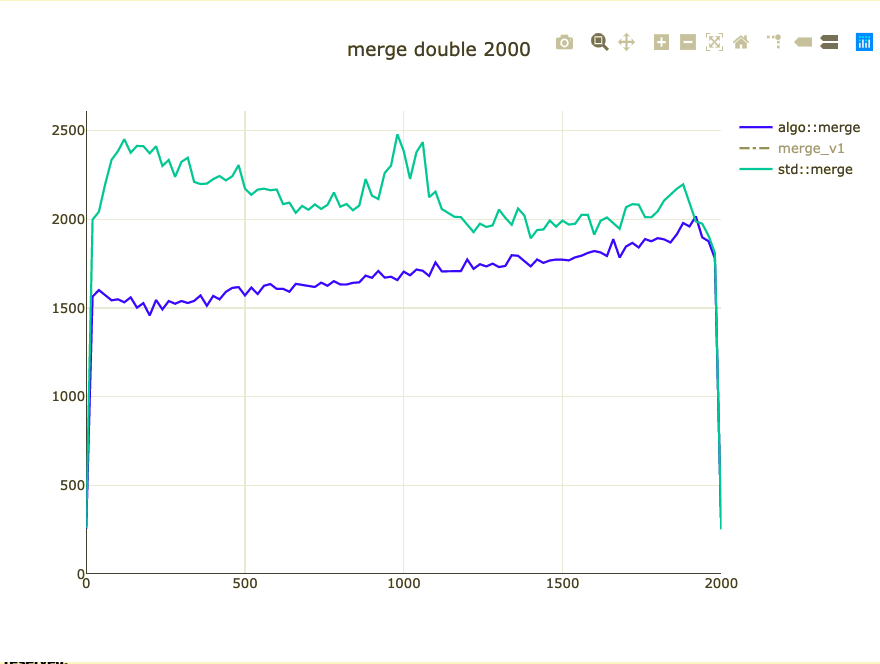
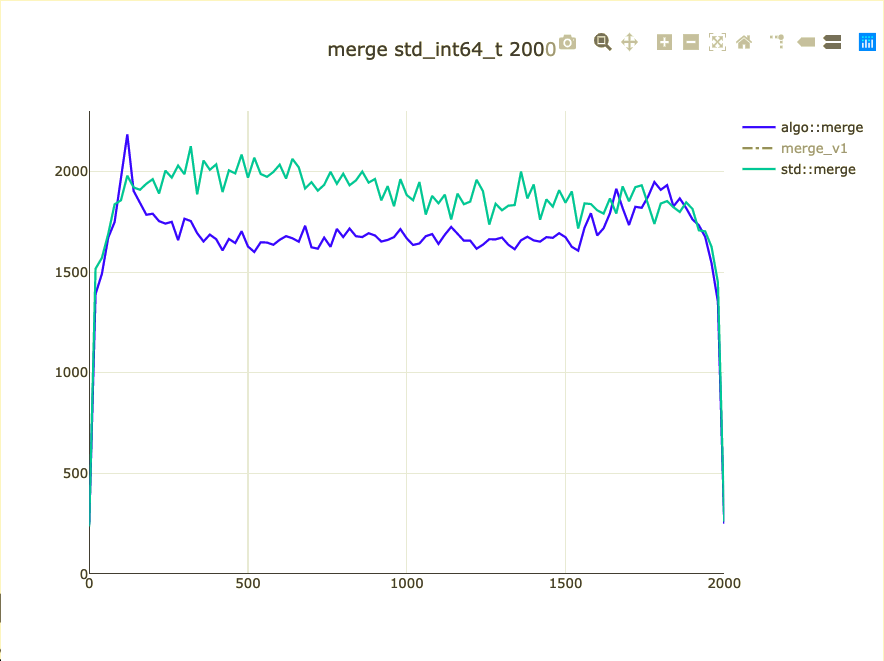
What to do about binary size?
We need to benchmark stable_sort
- Denis Bakhvalov's post on branches
- libc++ patch didn't land
- Compiler specific issues
- I have a similar set_union~ish algorithm
stable_sort
stable_sort is
- Memory adaptive merge sort
- Insertion sort (under 8 in libc++)
- Merge sort
- Merge sort "rotating middles"
What affects performance of sort?
- Total size
- How sorted is data already
- How many duplicates do we have
- Comparison
- Move
- Non templated operations
- Cache locality of data
- Binary size
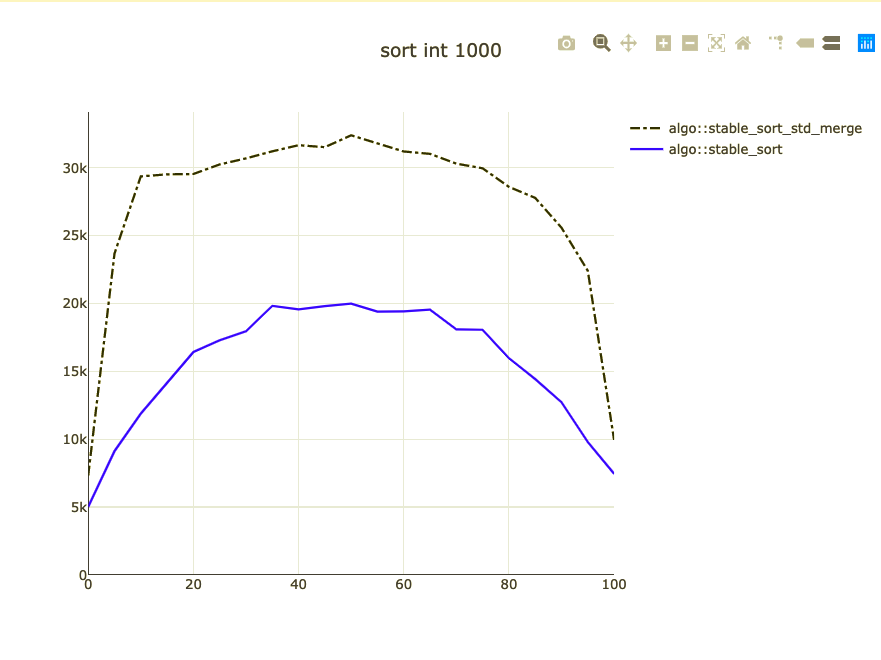
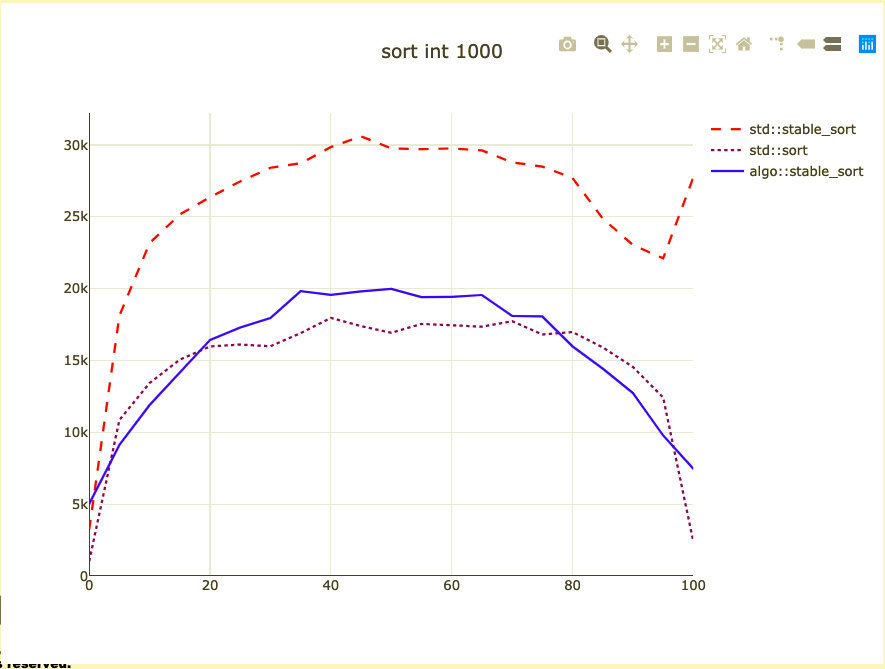
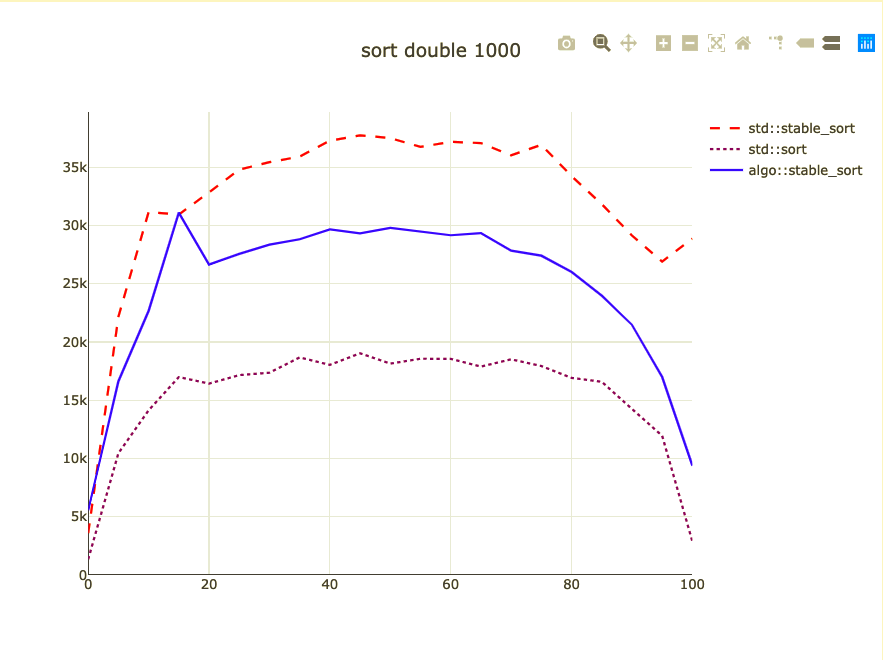
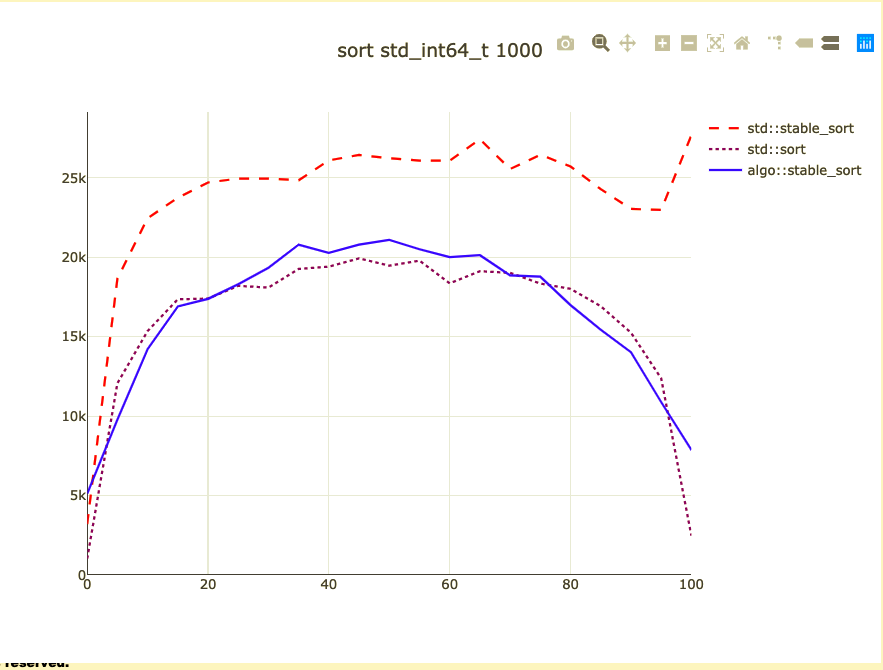
Basic sort benchmark
- Sort 1,000 integers
- Parameterized on how sorted they are
- I don't know how to address duplicates
- Double-check against code alignment
- Remove the baseline from benchmark
From sorted to reverse sorted?
- Lexicographical permutations (nth_permutation)
- Biased shuffle (bad) with reverse
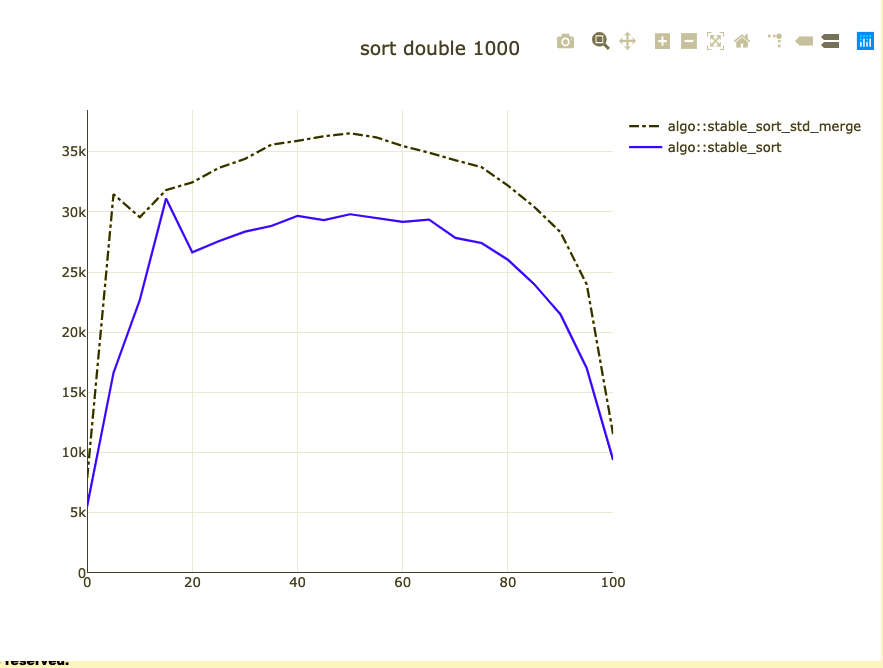
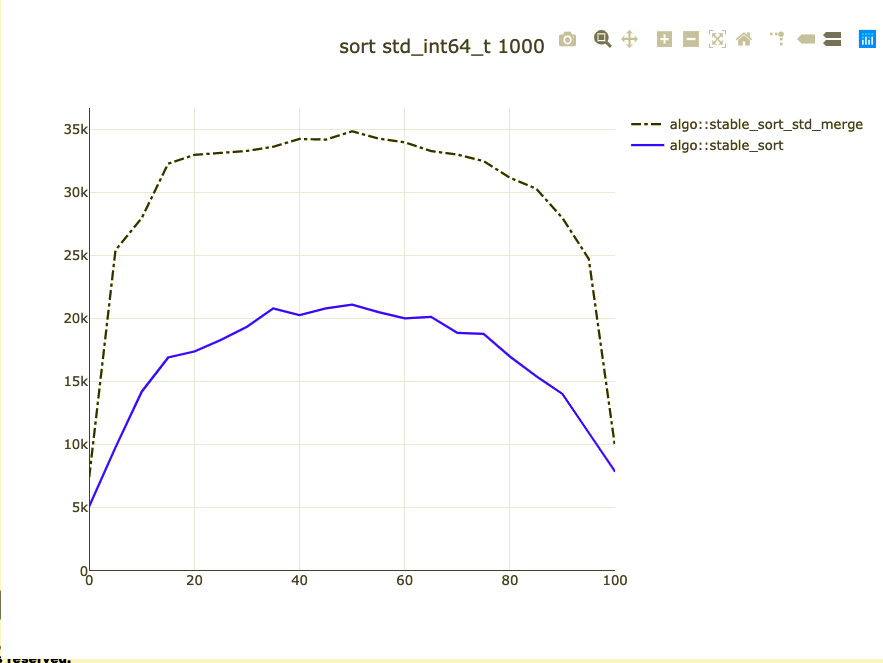
Possible bigger types
- fake_url: https://{number}.com
- fake_url pair
- noinline_int
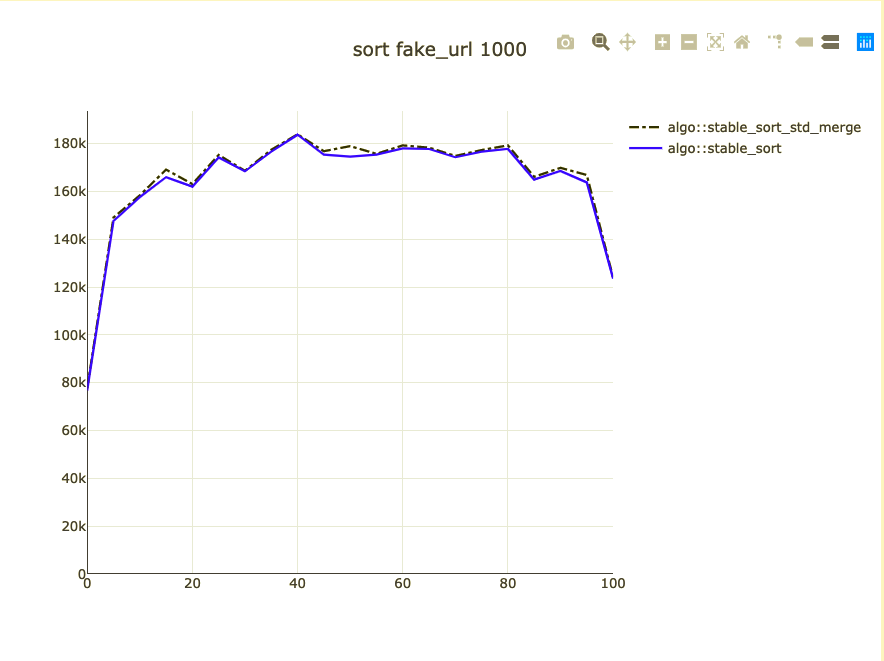
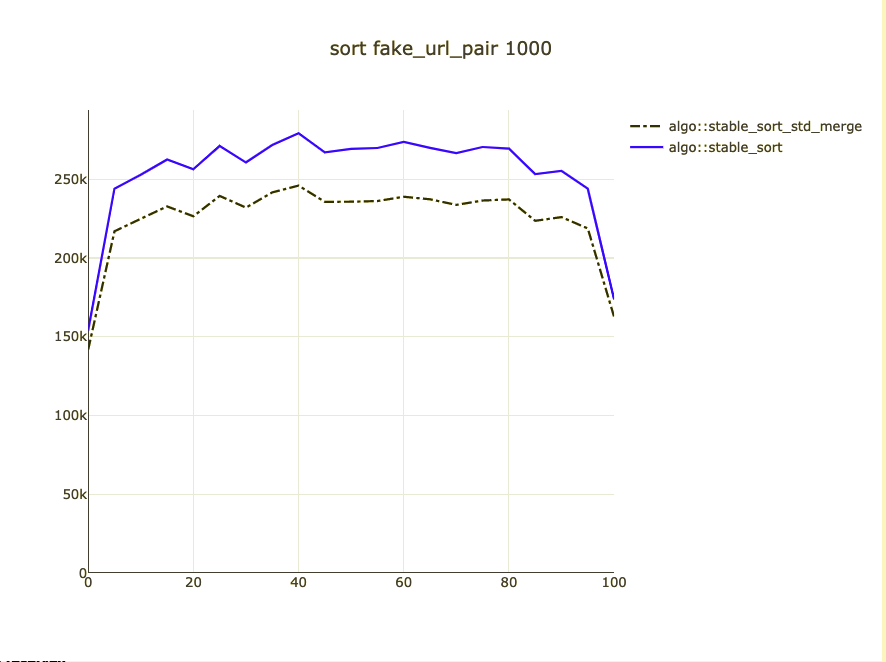
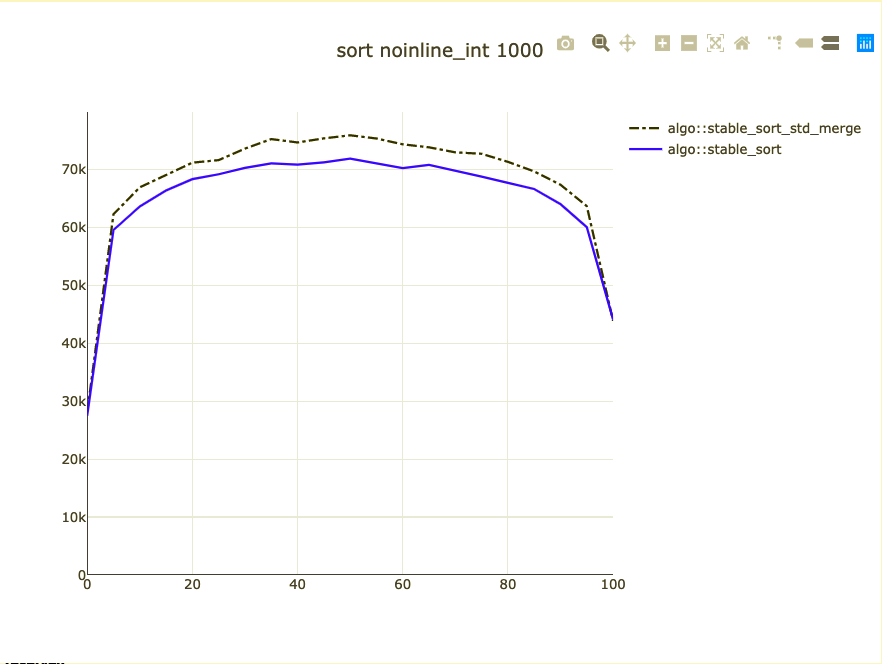
Sort pointers
- Rearrange underlying elements based on rearrangement of pointers
- Elements of programming, chapter 10: Rearrangements
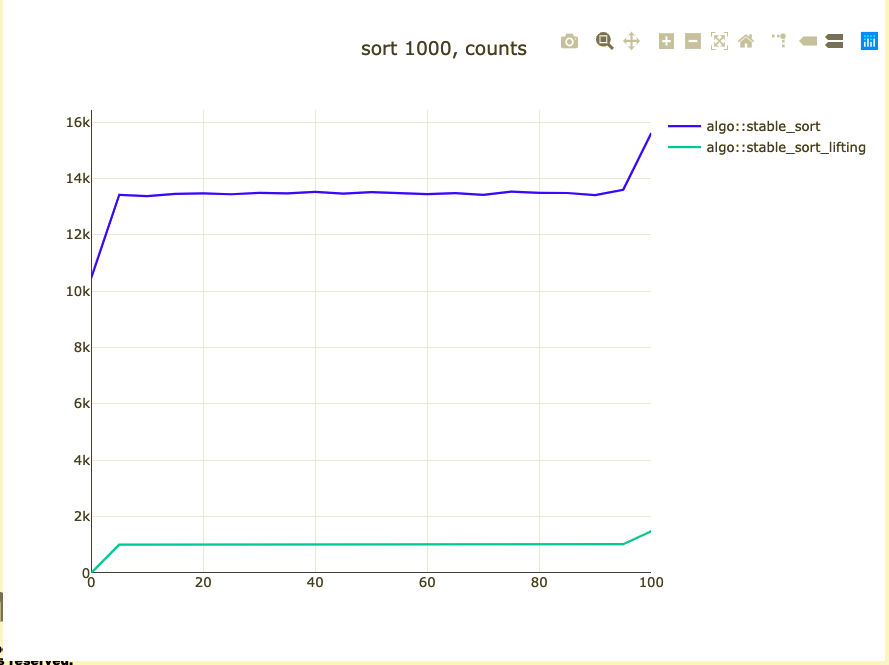
What did we affect?
- Move
- Non templated operations
- Cache locality of data
- Binary size
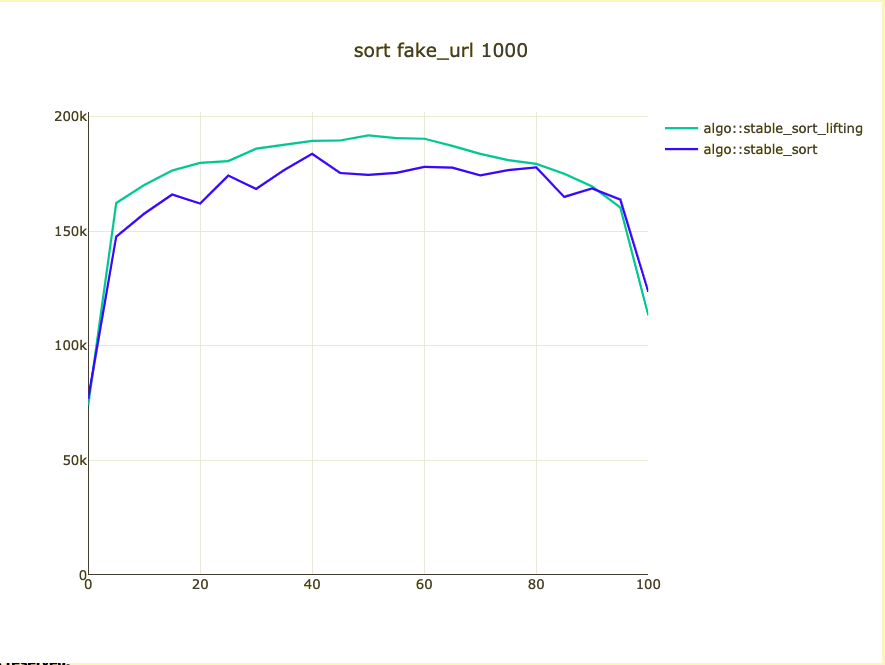
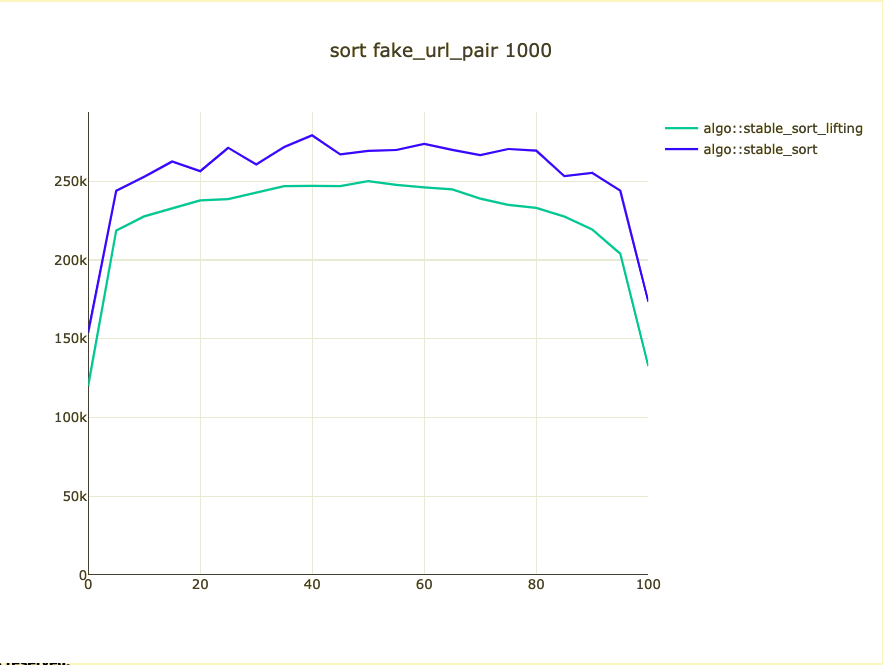
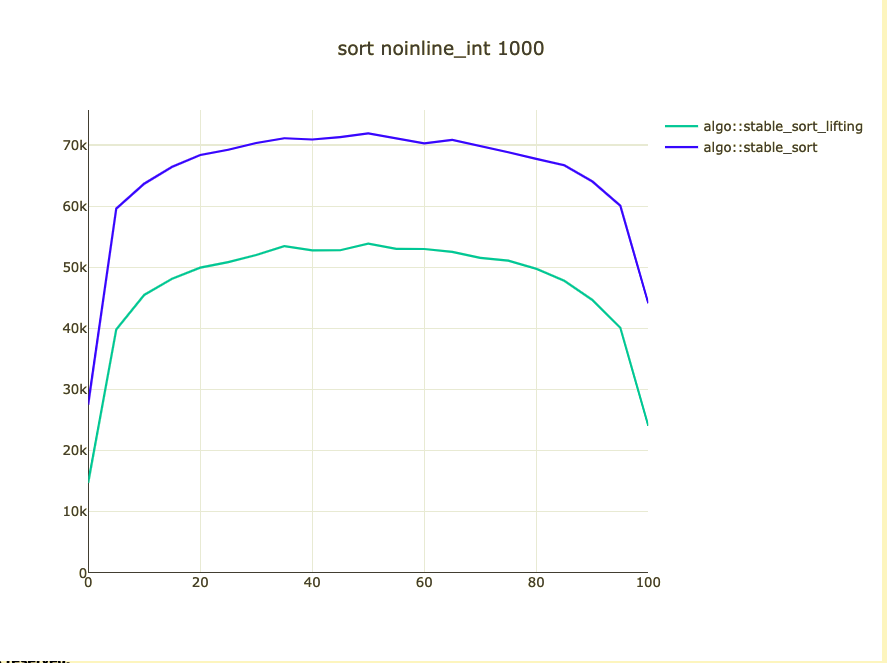
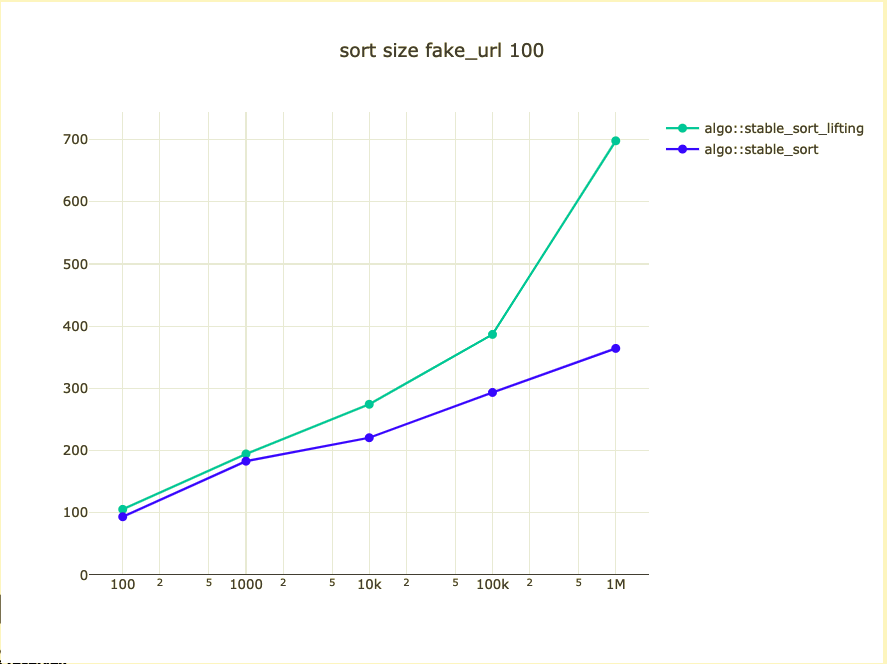
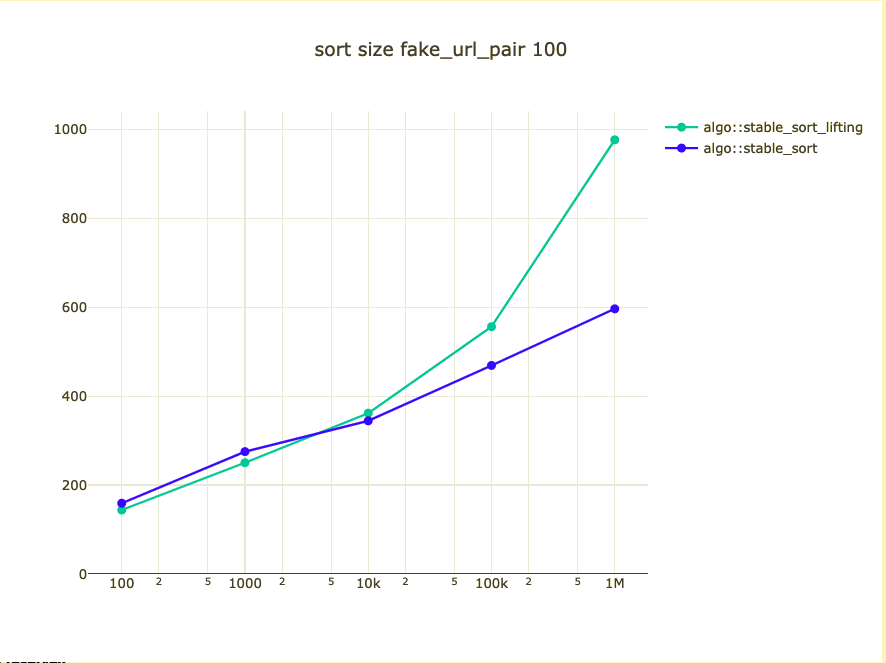
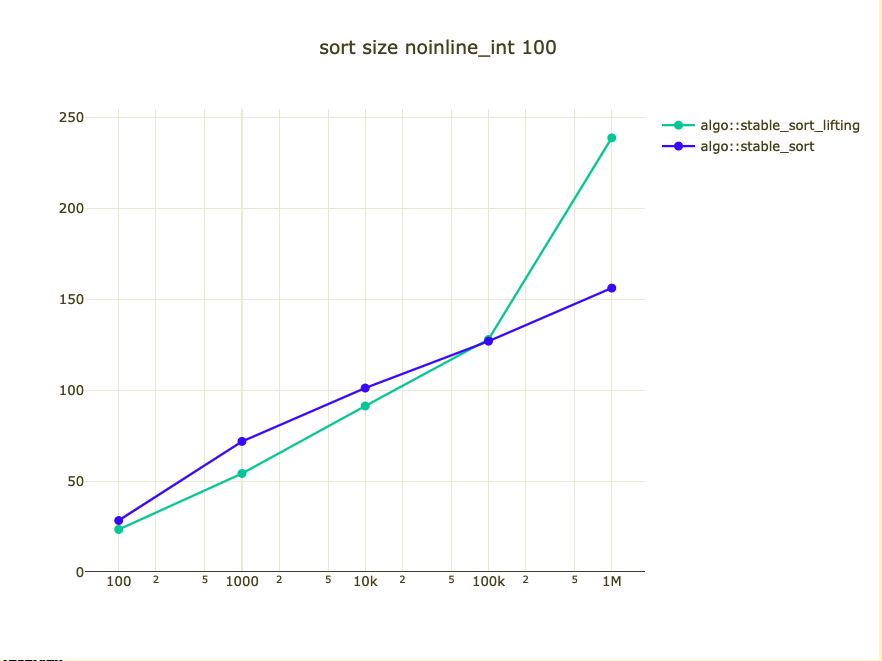
Could we/should we do it?
- Noinline move could be an intrinsic
- Move is bigger than copy bytes
- I need better implementations
- Pointer based rearrangement is powerful
Conclusions
How to optimize a generic component
- Analyze what can affect the performance
- Come up with an idea
- Build benchmarks for the basic case
- Build benchmarks for your optimization
- Build benchmarks for what could have been negatively affected
- Make the decision on the change
Some points
- Have a rationale for your optimization
- Benchmarks are very error-prone
- Small changes matter
- std::rotate could be improved
Where to learn about hardware/tools?
- Multiple blogs
- LLVM conference
- Matt Godbolt/Niall Douglas talks
Where to learn about algorithms?
- Alexander Stepanov's courses on A9 and Elements of Programming
- Competitive coding (code_report /geeksforgeeks.org)
- Andrei Alexandrescu "There's Treasure Everywhere"
- University courses online
Thanks to:
- Oleg Fatkhiev
- Denis Bakhvalov
Questions?
Code: https://github.com/DenisYaroshevskiy/algorithm_dumpster
Slides: https://tinyurl.com/y45sp8t2